클라우드 AI 서비스 자원 최적화: 개발자를 위한 효율적인 관리 전략
클라우드 환경에서 AI 모델을 개발하고 운영할 때 컴퓨팅 자원을 효율적으로 관리하는 것은 매우 중요한 역량입니다. AWS SageMaker와 GCP AI Platform을 중심으로 실무에 즉시 적용 가능한 최적화 팁을 알아봅니다.
AI 개발자에게 클라우드 자원 관리가 필수적인 이유
현업에서 AI 모델을 설계하고 학습시키는 과정은 필연적으로 막대한 컴퓨팅 자원을 요구합니다. 특히 대규모 데이터셋을 다루거나 딥러닝 모델을 훈련할 때 고성능 GPU 인스턴스를 장시간 사용하게 되는데, 이때 자원 관리에 소홀하면 불필요한 클라우드 과금이 폭증하는 상황을 맞이할 수 있습니다.
클라우드 서비스는 기본적으로 '사용한 만큼 지불하는' 구조로 운영됩니다. 따라서 실험이 끝난 후 유휴 상태인 노트북 인스턴스를 종료하지 않거나, 워크로드에 비해 지나치게 높은 스펙의 머신을 할당하는 실수는 곧바로 인프라 낭비로 이어집니다. 초기 아키텍처 설계 단계부터 자원 효율을 고려한 운영 계획을 수립하는 것이 성공적인 AI 프로젝트의 첫걸음입니다.

AWS SageMaker 실전 최적화 노하우
AWS 환경에서 기계 학습 워크플로우를 위해 널리 쓰이는 SageMaker는 강력한 기능을 제공하지만 세심한 관리가 필요합니다. 실무에서 가장 먼저 적용해야 할 팁은 수명 주기 구성(Lifecycle Configuration)을 활용하는 것입니다. 일정 시간 동안 사용자의 입력이나 실행이 없는 노트북 인스턴스를 자동으로 식별하고 종료하도록 스크립트를 설정하면, 개발자가 퇴근 후 켜둔 인스턴스에서 발생하는 유휴 자원 낭비를 완벽히 차단할 수 있습니다.
두 번째 핵심 전략은 매니지드 스팟 학습(Managed Spot Training)의 적극적인 도입입니다. 모델 학습 시 일반적인 온디맨드 인스턴스 대신 클라우드 내 남는 여유 자원인 스팟 인스턴스를 활용하면 동일한 성능의 컴퓨팅 파워를 훨씬 효율적인 방식으로 사용할 수 있습니다. 학습 작업이 클라우드 상황에 의해 중간에 중단되더라도 체크포인트(Checkpoint) 기능을 통해 멈춘 지점부터 이어서 학습할 수 있도록 코드를 구성하는 것이 중요합니다.

GCP AI Platform 기반의 스마트한 자원 할당
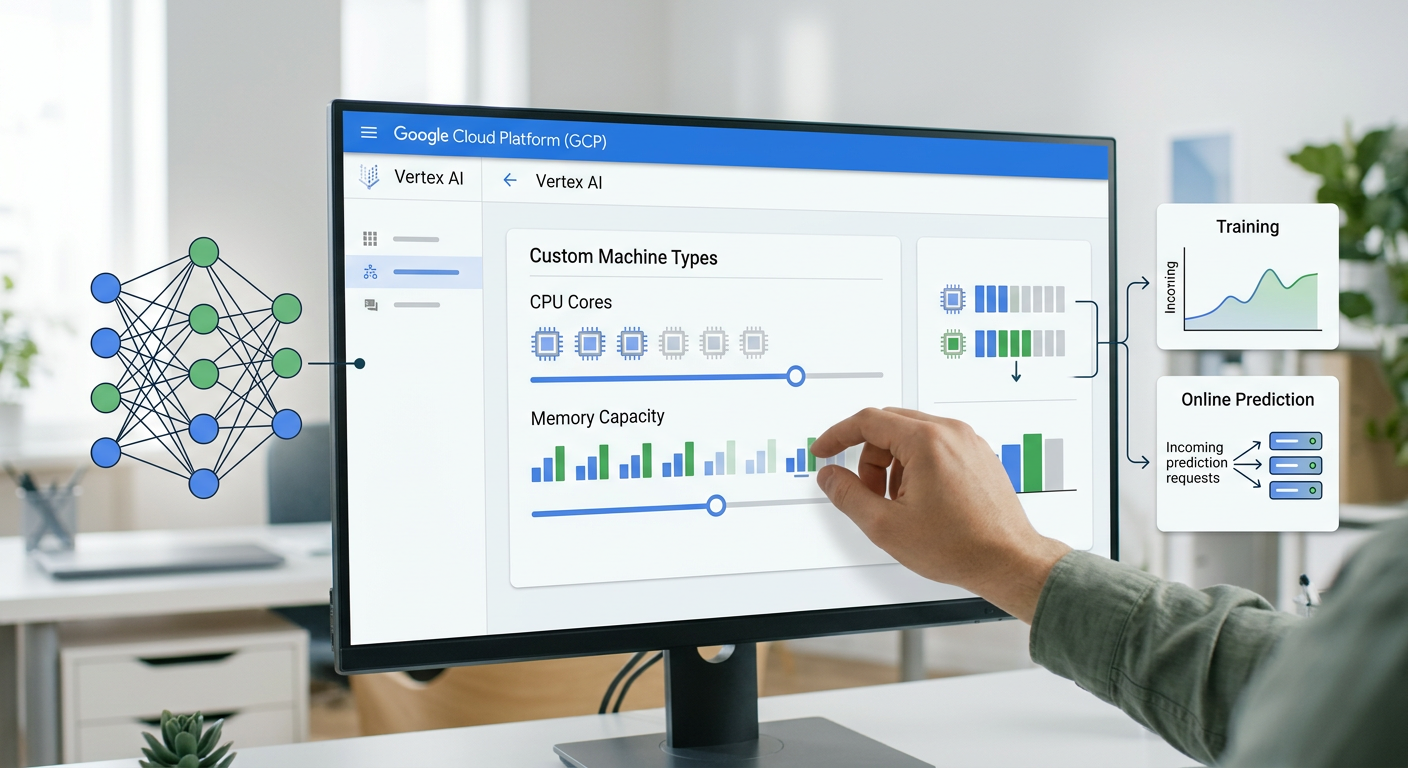
Google Cloud Platform(GCP)의 AI Platform 및 Vertex AI 환경에서도 실무적인 맞춤형 자원 관리가 가능합니다. 가장 유용한 기능 중 하나는 맞춤형 머신 타입(Custom Machine Types)입니다. 훈련시킬 모델의 특성에 맞춰 CPU 코어 수와 메모리 용량의 비율을 개발자가 직접 미세 조정할 수 있어, 미리 정해진 오버스펙의 인스턴스를 강제로 선택할 필요가 없습니다.
또한, 훈련된 모델을 배포하여 온라인 예측(Online Prediction) 엔드포인트를 운영할 때는 트래픽 변화에 따른 오토스케일링(Auto-scaling)을 반드시 설정해야 합니다. 특히 시스템 요청이 전혀 없을 때 활성 노드 수를 0으로 자동 축소하는 'Scale to Zero' 기능을 지원하는 환경이라면 이를 적극적으로 활용하여 불필요한 대기 리소스를 최소화할 수 있습니다.
지속 가능한 AI 파이프라인 구축과 개발자의 역할
앞서 살펴본 클라우드 인프라 최적화 전략은 단발적인 설정으로 끝나는 것이 아니라, 조직의 MLOps 파이프라인 전체에 유기적으로 녹아들어야 합니다. CI/CD 파이프라인 내에 자원 사용량 모니터링 시스템과 알람을 연동해두면, 코드 오류로 인한 무한 루프나 예상치 못한 자원 점유를 조기에 발견하고 대응할 수 있습니다.
저 김지섭은 AI 개발자로서 현업에서 다양한 모델을 연구하고 배포하며, 훌륭한 알고리즘을 설계하는 것만큼이나 인프라를 지혜롭게 다루는 것이 중요하다는 점을 매번 실감합니다. 이러한 클라우드 최적화 기술과 관리 노하우는 개발자가 한정된 환경 속에서도 더 다채로운 실험을 수행하고, 궁극적으로 서비스 가치를 높이는 뛰어난 AI 모델 개발에 집중할 수 있는 튼튼한 기반이 되어줄 것입니다.



