PyTorch를 활용한 실전 AI 애플리케이션 개발: 데이터셋 구축부터 배포까지 완벽 가이드

1. 프로젝트의 시작: 명확한 문제 정의와 데이터셋 준비
성공적인 AI 애플리케이션 개발은 코드를 작성하기 훨씬 전, '문제 정의' 단계에서 시작됩니다. 최신 AI 앱 개발 트렌드를 살펴보면, 단순히 모델을 돌리는 것보다 해결하고자 하는 문제를 명확히 하고 그에 맞는 데이터를 준비하는 과정이 전체 프로젝트의 성패를 좌우합니다. 이 과정은 구조화된 단계를 거쳐야 하며, 특히 '나만의 데이터셋(Custom Dataset)'을 어떻게 구축하느냐가 핵심 경쟁력이 됩니다.
PyTorch 생태계는 이러한 데이터 처리에 유연함을 제공합니다. 데이터를 수집했다면, 데이터 전처리(Preprocessing)와 증강(Augmentation)을 통해 모델이 학습하기 좋은 형태로 가공해야 합니다. 최근에는 생성형 AI를 활용해 부족한 데이터를 생성하거나, 반자동화된 라벨링 도구를 사용하여 데이터셋 구축 시간을 획기적으로 단축하는 방법도 널리 사용되고 있습니다. 탄탄한 데이터 파이프라인 없이는 아무리 좋은 알고리즘도 무용지물임을 기억해야 합니다.
2. 모델 학습과 최신 기술 트렌드: PyTorch와 YOLO의 진화
데이터가 준비되었다면, 다음은 모델 학습 단계입니다. PyTorch는 연구 목적뿐만 아니라 실무 개발에서도 가장 선호되는 프레임워크 중 하나입니다. 특히 컴퓨터 비전 분야에서는 객체 탐지(Object Detection) 기술이 비약적으로 발전했습니다. 최근 주목받는 YOLO(You Only Look Once) 모델의 경우, v8을 넘어 YOLO11에 이르기까지 경량화와 성능 향상이 동시에 이루어지고 있습니다. 과거와 달리 최신 YOLO 모델들은 PyTorch에서 네이티브로 구현되어 있어, 개발자들이 훨씬 쉽게 접근하고 수정하여 사용할 수 있게 되었습니다.
또한, 단순히 분류나 탐지 모델에 그치지 않고, KerasCV나 PyTorch를 활용해 스테이블 디퓨전(Stable Diffusion)과 같은 생성형 AI 모델을 파이프라인에 통합하는 시도도 늘고 있습니다. 이는 텍스트로 이미지를 생성하거나 기존 이미지를 변환하는 등 애플리케이션의 기능을 풍성하게 만듭니다. SOTA(State-of-the-art) 모델을 자신의 데이터셋에 맞춰 파인튜닝(Fine-tuning)하는 능력은 현대 AI 개발자에게 필수적인 역량입니다.

3. 서비스 배포와 운영: MLOps와 LLMOps의 도입
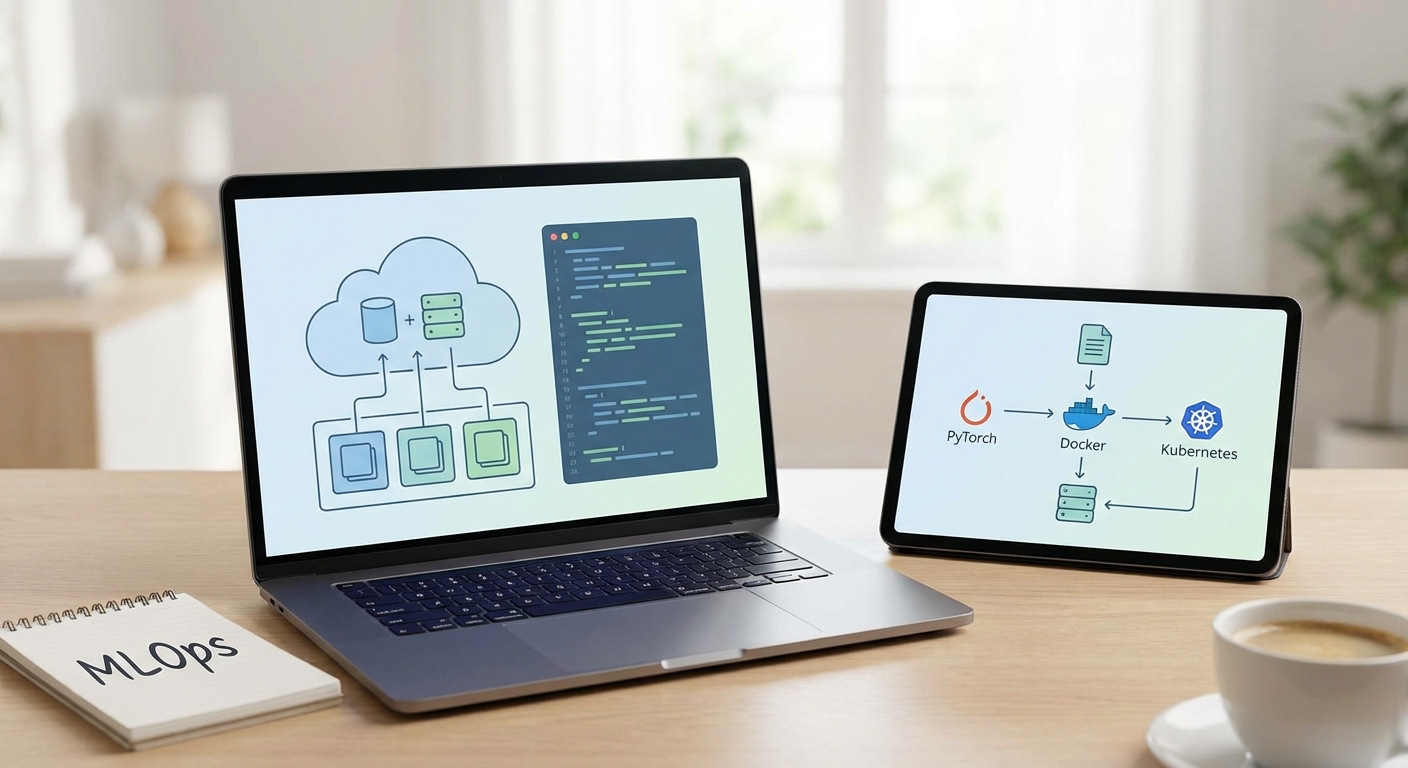
모델 학습이 끝났다고 해서 개발이 완료된 것은 아닙니다. 진정한 '애플리케이션'이 되기 위해서는 실제 사용자가 접근할 수 있는 형태로 배포되어야 합니다. 이 단계에서는 학습된 PyTorch 모델을 Django나 Spring Boot와 같은 웹/앱 프레임워크와 연동하는 작업이 필요합니다. 최신 개발 환경에서는 Docker와 Kubernetes를 활용하여 모델 서빙 환경을 구축하고, API 형태로 기능을 제공하는 것이 일반적입니다.
최근에는 단순 배포를 넘어 모델의 성능을 지속적으로 모니터링하고 관리하는 MLOps(Machine Learning Operations), 더 나아가 거대언어모델을 다루는 LLMOps의 중요성이 대두되고 있습니다. LLMOps는 모델의 생성, 배포, 관리를 전 수명 주기에 걸쳐 최적화하는 프로세스를 의미합니다. 모델이 실제 환경에서 접하는 데이터가 학습 데이터와 달라지는 현상(Data Drift)을 감지하고, 지속적으로 모델을 재학습 및 업데이트하는 파이프라인을 구축해야만 지속 가능한 AI 서비스를 운영할 수 있습니다.
4. 개발자 김지섭의 실전 팁: 기술 스택의 융합
AI 개발자로서 프로젝트를 진행하다 보면, 단순히 AI 모델링 지식만으로는 한계에 부딪힐 때가 많습니다. 저는 Django나 Spring Boot를 활용한 백엔드 개발부터, VR 기반 Unity 게임 개발, 그리고 최신 LLM 기반 챗봇 제작에 이르기까지 다양한 기술 스택을 넘나들며 프로젝트를 수행해왔습니다. 이러한 경험을 통해 얻은 결론은 '융합'의 중요성입니다.
성공적인 AI 애플리케이션은 AI 모델의 정확도뿐만 아니라, 이를 감싸고 있는 애플리케이션의 사용성과 안정성에서 판가름 납니다. PyTorch로 우수한 모델을 만드는 것에 그치지 않고, 이를 사용자가 편리하게 쓸 수 있도록 웹이나 앱 서비스로 매끄럽게 연결하는 '풀스택' 관점의 접근이 필요합니다. 기술의 경계를 두지 않고 다양한 도구를 유연하게 결합할 때, 비로소 사용자에게 실질적인 가치를 제공하는 AI 서비스를 완성할 수 있습니다.